

Big Data for Data Scientists
So you have seen big data related keywords mentioned countless times in data scientist job descriptions but don't know how to get started? Have you learned big data theory from MOOCs but still don't know how to build things? Sign up to learn about the Big Data course pricing and curriculum.
Associated learning paths:
Data Science- About the Course
- Learning Outcomes
- Course Resources
- Apply now
- Instructor
- Reviews
About This Course
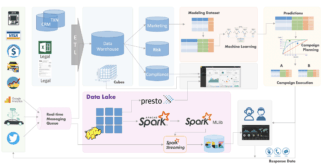
The Big Data for Data Scientists is a 12-week advanced-level project course that teaches data scientists the necessary tools to work with large-scale data science problems. The entire course is built around an end-to-end real-time machine learning problem. Students will learn the most cutting-edge big data frameworks and tools such as Apache Spark, Amazon SageMaker, Databricks, MLflow, Kafka, Elasticsearch, and Airflow. Students will also learn how to train machine learning models at scale and deploy models at scale in real-time.
WHO THIS COURSE IS FOR?

For Data Scientists
This course teaches you the big data skills you need to handle large data problems
For Machine Learning Engineers
This course has a focus on MLOps, Big Data, and Model Deployment on AWS
For Job Seekers and Career Switchers
This course teaches you how to build end-to-end big data and machine learning projects to enhance and elevate your data science portfolio
For Developers and Data Engineers
This course will enhance your knowledge of machine learning and big data at scale and teach you how to build scalable pipelines and data products

Learning Outcome
This advanced-level big data course teaches you the practical big data skills that you won't be able to learn anywhere else. It covers several important topics such as distributed computing, cloud, real-time data ingestion, machine learning at scale, as well as how to deploy and operationalize machine learning models in production. The curriculum is developed based on years of industry experience and reflects the most current industry trends and best practices. It will connect many dots for many data scientists.
Learning Outcome
Upon completing the course, students will be able to:
- 01. Understand Enterprise Data Flow
- 02. Query Big Data Lake
- 03. Master Apache Spark for Big Data
- 04. Machine Learning at Scale with Spark
- 05. AWS MLOps with SageMaker
- 06. Model in Production with Databricks, Docker, and MLflow
- 07. End-to-End Real-Time Project (Fraud Detection)
Be enterprise ready!
Only know textbook definition of big data? In this course, students will get familiar with the enterprise data architecture and pipelines of several industries. It gives the students a clear picture of where big data fits in and how it can work along with the traditional enterprise data architecture.
- Enterprise data flow in retail, banking, telecommunications
- Data lake vs Traditional EDW
Master important big data analytics tools
Whether you are tasked with using Hive to run ETL jobs, Presto/Athena as the query engine to build BI dashboards, or Easticsearch database to query log files, this module covers the essential tools and you will learn not only how to write queries but also when to use each tool
- Batch jobs with Apache Hive
- SQL on Hadoop with Presto and Amazon Athena
- Full-text and log queries with Elasticsearch
- Build real-time dashboards using Kibana and Superset
Dive deep into Apache Spark
Spark is the king of batch processing. It has replaced MapReduce and other frameworks in the past few years. With a focus on PySpark for Data Scientists, this course covers Spark RDD, DataFrame, and explains the internals of Spark for advanced users
- Work with low-level Spark RDD API for maximum flexibility
- Use Spark DataFrame for ETL, data transformations and preparation
- Write Pandas UDF to optimize Spark DataFrame operations
- Understand Spark DataFrame internals and query optimizations
- Learn Spark Structured Streaming to process near-real-time streaming data
- Learn the latest Kaolas API
Train and deploy machine learning models at large scale
Want to parallelize your scikit-learn jobs in Spark? Want to learn how to distribute parameter tunings? Want to learn how to train machine learning models on large datasets? This module covers Spark's Machine Learning API.
- Spark ML for Supervised Learning
- Spark ML for Unsupervised Learning
- Collaborative Filtering with ALS
- Model Persistent with Spark ML, MLleap, JPMML
Build production-grade ML pipelines
Amazon announced several exciting SageMaker features in the 2019 Re:Invent conference. We can't wait to include those in this course. This module teaches students how to leverage Amazon SageMaker to develop, train, scale, and deploy machine learning models in production.
- Collecting labels for ML with SageMaker Ground Truth
- Develop ML models using SageMaker Studio
- Train ML models and Tune parameters at scale using SageMaker
- Advanced Feature: Bring your own containerized models
- Deploy SageMaker models in batch and prediction services
Deploy and Monitor your ML Models
This module teaches students how to use MLflow and Spark on Databricks to deploy spark ML models and if your company has multiple ML frameworks on multi-clouds, MLflow is a great tool to deploy and manage your models.
- Dockerize your Sklearn/Tensorflow models
- Deploy your own model in SageMaker
- Model management with MLflow
Connect all the dots by implementing an awesome big data project
There's nothing textbook about our approach at WeCloudData. After learning so many tools and frameworks, it's important to know how to put everything together through an end-to-end project implementation
- Build an end-to-end real-time fraud detection pipeline using AWS, Kafka, Hive, Presto, Spark ML, Spark Streaming, Elasticsearch, and MLflow on Databricks
- Deploy the app in AWS
- Add the project to your big data portfolio
- Get referred to WeCloudData's hiring network upon completing the project
Course Resources
Check out the presentation below to learn more about the latest trends and use cases of big data.


Schedule
Instructors


What students are saying
I took the Big Data at Scale course with WeCloudData. The course introduces the latest big data tools and platforms such as Apache Spark and Amazon Web Services, as well as real-world use cases and industrial best practices. The course also includes an end-to-end group project which will definitely be something you can be proud of. I chose this course basically because my company uses Apache Spark and Hadoop distributed system, and I would like to learn more about it. Surprisingly, what I learned from this course has been far beyond my expectation! I wish I knew WeCloudData earlier so that I wouldn't have been that struggled at work. Before taking this course, I barely understood some log errors such as "Fail to start name node" and could only write simple queries in spark-shell. Now, I learned the theories behind and improved my programming skills. I am even capable to teach my peers colleagues some materials. Moreover, all the best practices and use cases taught in class gave me great insight of how to build pipelines efficiently and let me practice to think about the big picture of the design. It is actually something I appreciate the most since when I did the project, the overall design architecture just came into my mind immediately after my team defined the scope. I would also like to express my gratitude and appreciation to the instructor Shaohua in this course. He is extraordinarily knowledgeable and experienced, one of the best instructors I have ever seen! The way he approaches to a theory is really straightforward and easy to understand. He is nice and patient while answering questions as well and always makes sure every student is on the right track. The program managers of WeCloudData are kind and amiable too. It was a great pleasure to talk to them!
Grace
After listening and comparing big data courses in different places in Toronto, I went to sign up for all of the WeCloudData courses right after Shaohua’s info session without any hesitation. He is not only very knowledgable and experienced but also teaches so clearly and methodologically, which is way beyond my expectations. I have finished Python and big data courses up far, both courses are well-organized, project-oriented all along. You can start by applying what you have learned, exploring your own tools from there, and also building up step by step as you learn more throughout the courses. Whenever I got stuck, I could get all the help I need from the instructor, TA, and teammates, sometimes I also got motivated by other teams and pushed forward by my instructor to continue working on my project by doing in-class progress report and presentations. The things I have learned here and the final project presentation I did benefit me a lot by showing so much confidence in my big data interviews and helping me handing job offers. Quite often, I feel I know more than my interviewers! Many thanks to WeCloudData, it is a great learning platform with a great instructor, TAs and classmates!!
Wenle
I am a Data Science enthusiast, learning Data Science, Machine Learning, Deep Learning for the last couple of years. Besides doing online courses I have completed the Big Data at Scale from WeCloud data. I would highly recommend WeCloud Data to anyone who wants to learn practical/ applied Data Science and Big Data (Spark, Hadoop, AWS stack, Databases, SQL, NoSQL, Python, Machine Learning). Because I found the team of Shaohua (Instructor) very helpful. Shaohua is highly experienced in the field. The teaching style is very user-friendly where he breaks down difficult topics easy to understand.
M Chowdhury
I enrolled for the big data course with Instructor/Co-Founder Shaohua. Coming back java and C# programming background, big data was a new concept for me. The syllabus is well put together, comprising of labs and theory. I got to work on a project and present my findings to the class. I received good support during the entire coursework and felt encouraged to ask questions. All in all, I would recommend this course!
Hema Patil
This course really helped me with an in-depth explanation and application of Cloud and Big Data technologies. The lead instructor is very enthusiastic and gifted with years of industry experience as a chief data scientist. The course has a well-designed with systematic curriculum structure where you get to learn each component of the Big Data Ecosystem with a big picture of the whole Machine-Learning pipeline (online and offline).
Jason Lee
WeCloudData is intense... in a great way. Shaohua is experienced and leads an impressive team of instructors. The course material and the exercises are demanding, so you should be serious about a career in data science before you enrol. Unlike a lot of other data science bootcamps, WeCloudData also has advanced courses for people who are already working in the industry. Five stars.
Mark
Reach out for a Free Consultation